构造FP-Tree
挖掘频繁模式前首先要构造FP-Tree,算法为码如下:
输入:一个交易数据库DB和一个最小支持度threshold.
输出:它的FP-tree.
步骤:
1.扫描数据库DB一遍.得到频繁项的集合F和每个频繁项的支持度.把F按支持度递降排序,结果记为L.
2.创建FP-tree的根节点,记为T,并且标记为’null’.然后对DB中的每个事务Trans做如下的步骤.
根据L中的顺序,选出并排序Trans中的事务项.把Trans中排好序的事务项列表记为[p|P],其中p是第一个元素,P是列表的剩余部分.调用insert_tree([p|P],T).
函数insert_tree([p|P],T)的运行如下.
如果T有一个子结点N,其中N.item-name=p.item-name,则将N的count域值增加1;否则,创建一个新节点N,使它的count为1,使它的父节点为T,并且使它的node_link和那些具有相同item_name域串起来.如果P非空,则递归调用insert_tree(P,N).
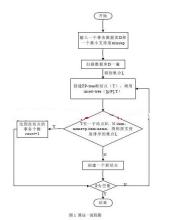 FP-Tree创建的算法流程图
FP-Tree创建的算法流程图
注:构造FP-Tree的算法理解上相对简单,所以不过多描述
挖掘频繁模式
对FP-Tree进行挖掘,算法如下:
输入:一棵用算法一建立的树Tree
输出:所有的频繁集
步骤:
调用FP-growth(Tree,null).
procedure FP-Growth ( Tree, x)
{
(1)
if (Tree只包含单路径P)
then
(2) 对路径P中节点的每个组合(记为B)
(3) 生成模式B并x,支持数=B中所有节点的最小支持度
(4) else 对Tree头上的每个ai,
do
{
(5) 生成模式B= ai 并 x,支持度=ai.support;
(6) 构造B的条件模式库和B的条件FP树TreeB;
(7)
if TreeB != 空集
(8)
then call FP-Growth ( TreeB , B )
}
}

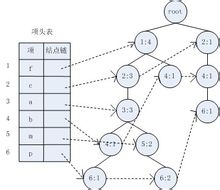 FP-Tree结构图
FP-Tree结构图